
What AI do you actually have?
You can't govern AI if you don't know where it actually lives


TL;DR
The article makes four claims that matter.
Claim 1: Most organisations have a large AI estate they do not fully see, so governance is being built on partial visibility rather than a full map of what exists.
Claim 2: The real AI estate splits into three zones - what you control, what vendors add and what runs on other people’s infrastructure - and each zone allows a different governance response.
Claim 3: Mapping comes before response. You cannot avoid, mitigate, transfer or accept AI risk until you know which tools, features and dependencies are actually in the estate.
Claim 4: The practical fix is a populated estate map with a named owner, a zone, a data classification and a status for each entry. The article’s point is that the production layer only works after that map exists.
Yesterday, Neil Catton dropped a note that really struck me.
He was commenting on the Production Layer methodology I use to move AI from pilot to governed, production-grade deployment. His observation was short and precise:
The production layer argument assumes the organisation knows what it’s governing. That’s the harder problem.
He is right. And the more I pulled on that thread, the more uncomfortable it got.
Enterprises are spending real money on AI governance: policies, control planes, responsible AI frameworks, TRiSM platforms, AI Business Offices. Most of it is being deployed on top of a false premise that the AI estate is visible and owned.
In reality, most organisations have never fully mapped what AI they actually run, who brought it in, or how much of it sits on infrastructure they do not control.
The result is predictable: serious governance effort concentrated on the visible tip of the estate, and very little grip on where AI is actually used, which tools touch sensitive data, or how much of the risk sits on someone else’s servers.
Neil named the crux. This article is what I found when I went looking for evidence that he was wrong. And didn’t find it.
The comforting lie in AI governance
Every serious risk framework starts in the same place: first identify and assess your risks, then choose how to treat them. In the language of NIST, ISO, and ISACA, that means you map the problem before you pick between four responses: avoid, mitigate, transfer, or accept the risk.
AI governance decks or vendor pages say the same thing in more modern language: “visibility first,” “AI inventories,” “control towers,” “discovery engines.”
You are told to start with an inventory of models, tools and data flows, then apply policies and controls.
But when you look at what is actually happening inside enterprises, the order is often reversed.
Zluri’s 2025 State of AI in the Workplace report found that employees in a typical mid‑ to large‑size organisation now use dozens or hundreds of AI tools, yet IT and security teams have visibility into fewer than 20 percent of them.
Protiviti’s 2026 AI Pulse survey reports that 47 percent of large organisations admit they do not have full visibility into the AI tools their employees use, and 65 percent say “shadow AI” is now a material challenge.
Shadow AI - AI tools and features adopted without IT approval - is now a standard term in security and compliance guidance, and almost every new data‑security product starts its pitch with some version of “you can’t protect what you can’t see.”
The comforting lie is that “visibility first” is already true. On the ground, most organisations are still at “visibility later, maybe.”
What is actually in the AI estate?
When you strip away the marketing language, the AI inside a typical enterprise shows up through six main entry points:
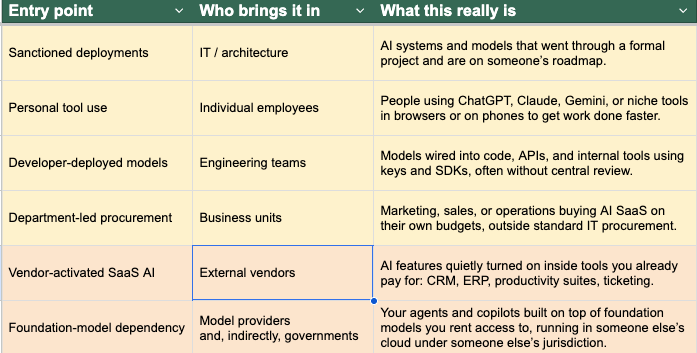
The top four rows are “home‑grown” in different ways. They are all created or adopted by your own staff, even if nobody asked permission.
The bottom two rows arrive from the outside: vendors push AI into your existing tools and foundation model providers sit underneath your own AI stack.
Most governance tools and frameworks you see today are built for the “home-grown”. They assume the “AI you care about” is the “AI you built or explicitly bought”. The problem is that a large amount of your exposure now shows up in the bottom rows - where you use AI, but you do not fully own the systems it runs on.
A real mandate that started from the map
I mention this use-case before. Inside one global engineering group, a VP is sitting on roughly 500 AI‑adjacent engineering projects. The “AI pipeline” works, the data platform and master‑data systems are there and technically sound.
What is missing is governed master data and a living data community. The people and incentives that keep business data structured and owned.
Their own description of the mandate is 80-90 percent data governance, 10–20 percent AI. Success is defined as
the number of master‑data domains brought back under governance,
the quality indicators attached to each, and
a community that is not administrative theatre but a real network with time, mandate and skin in the game.
In other words: they do not need another AI architecture.
They need someone to map what exists, re‑attach ownership to that data and rebuild the human system around it. Only then does the AI production layer make sense.
It may sound like an outlier. Yet, it is the quiet pattern under a lot of “AI transformation” work that rarely makes it into conference talks.
Where risk management meets AI governance
Once you look at AI through the six entry points, the governance problem is no longer one question but rather three - each requiring a different response.
A quick reminder. Risk management gives you four responses once you have identified a risk: avoid it, mitigate it, transfer it, or accept it. All four actions are legitimate. None works until you have mapped the risk first.
That is the problem.
You cannot avoid a tool you do not know exists.
You cannot mitigate data exposure from a vendor feature you have not audited.
You cannot formally accept a foundation-model dependency that has never appeared in a risk register.
The three estate zones define which responses are actually available to you.
Zone 1 - estate you can actually control
This zone covers the first four rows of the table: allowed deployments, personal tools, developer models and department‑led SaaS. The common property is simple: these are all inside your organisation’s formal authority. With the right mandate, policy, and technical controls, you can change how they are used.
This is where my production‑layer methodology, AI Business Office and control planes make sense. Because you can:
decide which AI tools are allowed and on what terms,
route approved AI traffic through gateways and proxies,
require developers to register model API keys in CI/CD and
link AI access to identity and access‑management.
In risk‑framework terms, Zone 1 is where avoid and mitigate are real options. You can decide not to allow a class of tools. You can reduce the chance or impact of misuse with controls.
Once you have that list, the next step is accountability - naming the human who owns each consequential decision an AI system makes. That is a separate exercise, covered separately:

Zone 2 - estate you inherit from vendors
Vendor‑activated SaaS AI sits in the fifth row. You did not buy “AI” explicitly. You bought a CRM, an ERP, a ticketing tool or a productivity suite. The vendor added AI into it later.
Here, you can’t pretend you are fully in control. You cannot rewrite the SaaS product. But you are not powerless. The work in Zone 2 is to:
decide, per feature, whether to keep it on, turn it off or fence it with strict data rules,
enforce data‑loss‑prevention and data‑masking policies at the network layer so sensitive fields do not flow into vendor AI features by default,
use contract renewals to negotiate tenant‑level disable rights and training‑data exclusions where the relationship is big enough to give you leverage.
In risk terms, you cannot fully control the product, but you can avoid features, mitigate data exposure and transfer some responsibility through contracts and indemnities.
Zone 3 - estate that runs on other people’s infrastructure
Your agents, copilots and AI-enabled workflows run on foundation models you do not own, in clouds you do not operate, under laws you do not write. A government decision can change who gets access to a model over a weekend.
You have less options than in Zones 1 and 2. You can avoid single-provider dependency. You can mitigate through hot-swap architecture, though that is a 12–18 month investment. You can transfer financial exposure through contracts, but not regulatory accountability.
Whatever remains has to be formally accepted at board level - documented, owned, reviewed.
This is where AI procurement and geopolitical risk management meet.
What does mapping look like?
The output of this work is a list — a populated version of the table above with your actual AI estate in it: tool or system name, which zone it sits in, what data it touches, who owns the governance decision, and current status. That list is the map. Everything else, such as the risk responses, the controls, the contracts - comes after it exists.
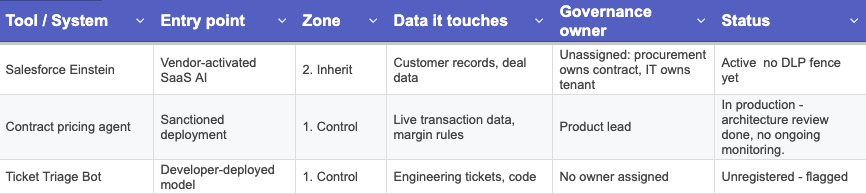
Most organisations skip straight to "respond" before this list exists.
The mapping comes first: CASB (cloud access security broker) telemetry and expense data for Zone 1, a SaaS feature audit for Zone 2, an impact score per foundation-model dependency for Zone 3.
Only then does it make sense to ask which risks to avoid, mitigate, transfer or accept.
Three 90-day tests
Here are three tests any executive team can run in a quarter.
The visibility ratio
If you have a cloud access security broker (CASB), pull its discovery report.
If you do not, pull SaaS spend from finance.
If you have neither, you do not have the instrumentation to run the test.
If your CASB or expense data show AI tools your registry does not contain, those are your governance gaps. The size of that list tells you where you actually stand.
Decision speed test
Within 90 days, take the top 5 unsanctioned AI tools you found and see whether each is classified as approve, restrict, replace or block with an owner and deadline. If everything is still under review at day 90, you do not have governance.
Control test
Pick one high-risk AI use case - like tools handling corporate data - and check if the policy, approval path and technical control actually stop unsanctioned use or force migration.
If people can keep using the tool unchanged after the review, the policy is ignored.
If you cannot answer those questions, you do not have an AI governance problem. You have an unpriced concentration risk sitting outside your risk register.
What this means for operators
If you are a CIO, CISO, CDO or COO, the next 6–12 months of real work is not another control plane or another policy document. It is the slow, political, unglamorous work of mapping what you actually have. And forcing three honest questions into the open:
which AI do we stop using,
which exposure do we accept because the business value justifies it, and
which foundation-model bets are we making knowingly versus by default.
Once you have answered those questions and made a conscious decision at the right level, the production layer makes complete sense. It was never wrong. It was built for the part of the estate you can see and own.
The work now is to find out how small that part really is, and start governing the AI you actually have.
My final ask
These Signals come from conversations I have with executives every week. Just written down.
If this one named something you have been circling without landing on - send it to the person closest to the first agent deployment decision. They need to read it before they approve it.
And if you want to support the work directly:
Great follow up article and thanks for recognising there is more to the challenge of AI than people realise at first glance.
You've mapped the estate problem clearly, Andrei. Reading it raised something I think sits just below even the visibility question: data we don't yet know we have, and can't plan for.
We have well-established frameworks for governing data we can identify and classify. Lineage, provenance, quality standards — these work when data has a known origin and a traceable path. Generative AI is creating a category of data object that our current vocabulary and governance models have no proper name for.
When AI models start populating data products and marketplaces with synthetically generated outputs, the lineage question becomes hard in a new way. Where did that data object come from? What rules produced it? Which model version, trained on what, with what parameters? A human analyst can be interviewed. A data source can be audited. A synthetic data object generated by an opaque model chain is something else entirely — and we don't yet have a clean answer to how you certify its provenance or its fitness for use downstream.
The governance work you've described is the right first move. But I think we've started at the top of the problem: AI as technology, then as a functional capability, then embedded in business processes. The harder layer is at the bottom — the data substrate everything rests on. That's where the real governance challenge lives, and it's the layer we haven't properly reached yet.
Which matters beyond AI: if we can't solve synthetic data lineage now, at a scale we can still examine and understand, we won't stand a chance when quantum computing starts generating data objects at a complexity that makes today's generative AI output look manageable.
Important points!